

Fail Safe, Fail Smart… Succeed! (Part 3 of 3)
Fail Safe, Fail Smart… Succeed! (Part 3 of 3)

This is part three of Chapter 1 from It Depends: Writing on Technology Leadership 2012-2022. Part two was published yesterday, and part one the day before. I had to break it up so your e-mail reader wouldn't truncate it.
Expect failure all the time
There is a substantial difference in how we discuss failure in the context of software development from the year 2000 compared to today. Back then, you worked hard to write robust software, but there was an expectation of hardware reliability. So, when a hardware failure occurred, the software's fault tolerance was of incidental importance. Of course, you didn't want to cause errors yourself, but if the platform was unstable, there wasn't much you were expected to do about it.
Today we live in a world with public clouds and mobile platforms where the environment is entirely beyond our control. Amazon's Web Services platform taught us a lot about handling system failure. A blog post from Netflix about their move to AWS was pivotal to the industry's adapting to the new world. The blog post discusses how Netflix had to change their perception of how services work because Infrastructure as a Service platforms like AWS work very differently to traditional corporate data centers.
Netflix's approach to system design has been so beneficial to the industry. We now assume that everything can be on fire all the time. You could write perfect software, and the scheduler will still come and kill it on mobile. AWS will kill your process, and your service will be moved from one pod to another without warning. We now write our software expecting failure to happen at any time.
We've learned that writing large systems complicates handling failure, and one of the reasons micro-service architectures have become more prevalent is to help us be failure safe. Why? Because they are significantly more fault-tolerant, they fail small when they fail. Products like Amazon, Netflix, and Spotify all have large numbers of services running. A customer doesn't notice if one or more instances of the services fail. When a service fails in those environments, it is responsible for a small part of the experience. The other systems assume it can fail. There are things like caching to compensate for a system disappearing.
Netflix has its famous chaos monkey testing, which randomly kills services or even entire availability zones in their production environment. These tests make sure that their systems fail well.
An architecture composed of smaller services that are assumed to fail means that there is near zero user impact when there is a problem. Therefore, failing well is critical for these services and their user experience.
Smaller services also make it possible to use DevOps techniques such as progressive rollout, feature flags, dark launching, blue-green deploys, and canary instances, making it easier to build in a fail-safe way.
My Biggest Failure
If you are a long-time Spotify user, you probably won't recognize the interface shown in the photo below. In May of 2015, though, Spotify was very interested in telling the whole world about it. It was a new set of features in the product called "Spotify Now."
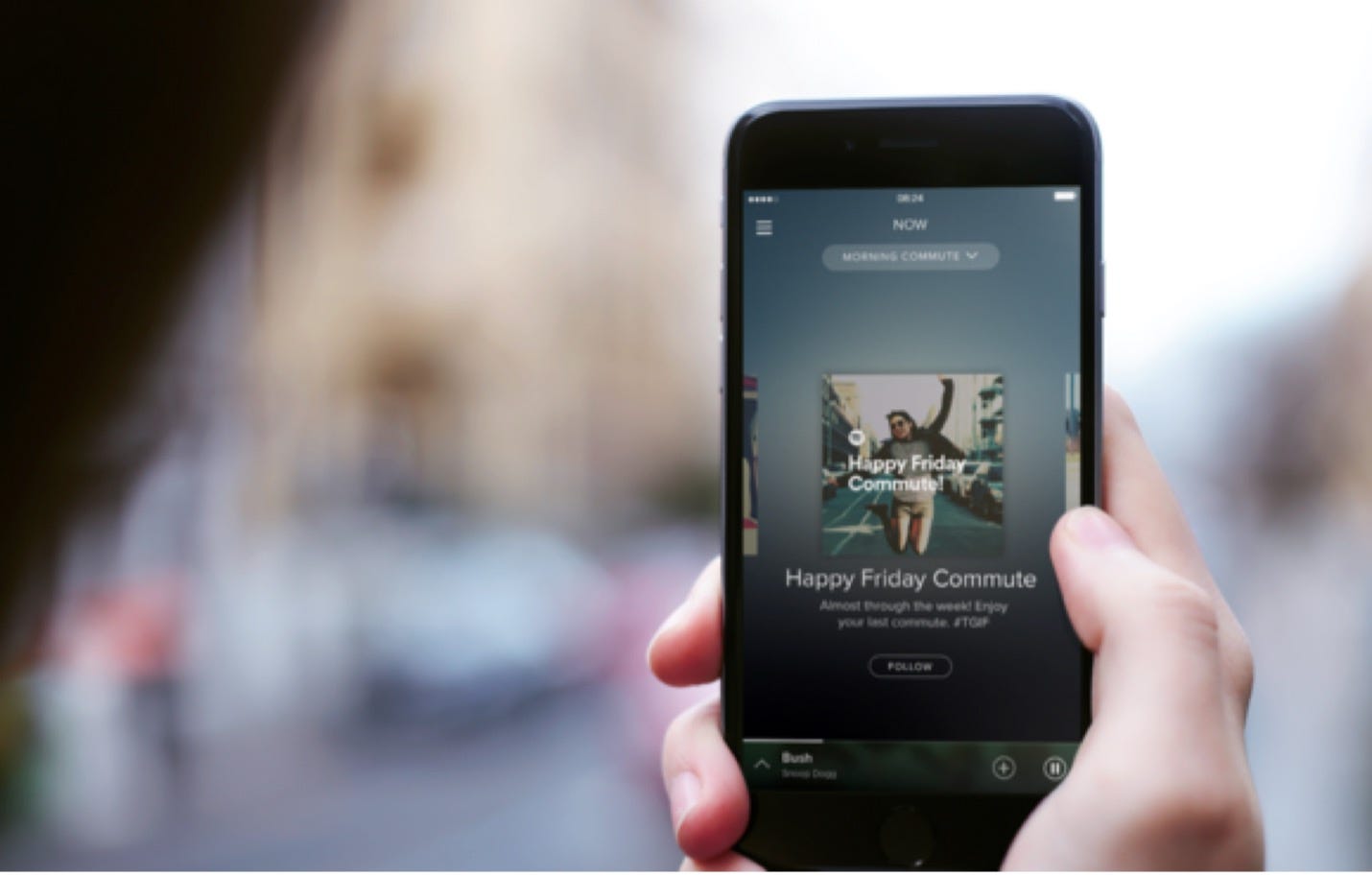
I led the engineering effort at Spotify on the Spotify Now set of features. It was the most extensive concerted effort that Spotify had done to that time, involving hundreds of employees worldwide.
Spotify Now was a set of features built around bringing the perfect, personalized music for every user for every moment of the day. This effort included adding video, podcasts, a Running feature, a massive collection of new editorial and machine learning-generated playlists, and a simplified user interface for accessing music. It was audacious for a reason. We knew that Apple would launch its Apple Music streaming product soon. So, we wanted to make a public statement that we were the most innovative platform. Our goal was to take the wind out of Apple's sails (and sales!)
Given that this was Spotify, we understood how to fail smart.
As we launched the project, I reviewed the project retrospective repository. I wanted to see what had and had not worked on large projects before. With that knowledge, I was now prepared to make all new mistakes instead of repeating ones from the past.
We had a tight timeline, but some features were already in development. I felt confident. However, there was a growing concern as we moved forward, and the new features started to take shape in the employee releases. We worried the new features wouldn't be as compelling as the vision we had for them. We knew that we, as employees, were not the target users of Spotify Now. We were not representative of our users. To truly understand how the functionality would perform, we wanted to follow our usual product development methods and get the features in front of real customers to validate our hypotheses.
Publicly releasing the features to a narrow audience was a challenge at that time. The press, aware of Apple's impending launch, closely watched every Spotify release. They knew that we tested features and were looking for hints of what we would do to counter Apple.
Our marketing team wanted a big launch event. This release was a statement. We wanted a massive spike in Spotify's press coverage, extolling our innovation. The response would be muted if Spotify Now leaked before the event.
There was pressure from Marketing not to test the features, but Product Engineering wanted to follow our standard validation processes. Eventually, we found a compromise. We released early versions of Spotify Now to a relatively small cohort of New Zealand users. Then, satisfied that we were now testing the features in the market, we went back to building and preparing for the launch while waiting for the test results.
After a few weeks, we got fantastic news. Our cohort's retention was 6% higher than the rest of our customer base.
Customer retention is the most critical metric for a subscription-based product like Spotify. It determines the Lifetime Value of the customer. The longer you use a subscription product, the more money the company will make.
With a company of the scale of Spotify, it was tough to significantly move a core metric like retention. A whole point percentage move was rare and something to celebrate. With Spotify Now, we had a 6% increase! It was a massive result.
Now, all our doubt was gone. We knew we were working on something exceptional. Finally, we'd validated it in the market! With real people!
On the launch day, Daniel Ek, Spotify's CEO and founder; Gustav Söderstrom, the Chief Product Officer; and Rochelle King, the head of Spotify's design organization, shared a stage in New York with famous musicians and television personalities. They walked through everything we had built. It was a lovely event. Simultaneously, I shared a stage in the company's headquarters in Stockholm with Shiva Rajaraman and Dan Sormaz, my product and design peers. We watched the event with our team, celebrating.
As soon as the event concluded, we started the rollout of the new features by releasing them to 1% of our customers in our four most significant markets. We'd begun our Ship It phase! We drank champagne and ate prinsesstårta (my favorite Swedish cake).
I couldn't wait to see how the features were doing in the market. After so much work, I wanted to start the progressive rollout to 100%. Daily, I would stop by the desk of the data analyst who monitored the metrics. He sent me away for the first couple of days with the comment, "it is too early still. We're not even close to statistical significance." Then one day, instead, he said, "It is still too early to be sure, but we're starting to see the trend take shape, and it doesn't look like it will be as high as we'd hoped." Every day after, his expression became dourer. Finally, it was official. Instead of the 6% increase we'd seen in testing, the new features produced a 1% decrease in retention. It was a 7% difference between what we had tested and what we had launched.
Not only were our new features not enticing customers to stay longer on our platform, we were driving them away! To say that this was a problem was an understatement. It was a colossal failure.
Now we had an enormous quandary. We had failed big instead of small. We had released several things together, so finding the problem was challenging. Additionally, we'd just had a major press event where we talked about all these features. There was coverage all over the internet. The world was now waiting for access to what we had promised, but we would lose customers if we rolled them out further.
Those results began one of the most challenging summers of our lives. First, we had to narrow down what was killing our retention in these new features. Then, we had to start generating new hypotheses and running tests within our cohort to find out what had gone wrong.
The challenge was that the cohort was too small to run tests quickly (and it was shrinking daily as we lost customers). Eventually, we had to do the math to determine how much money the company would lose if we expanded the cohort so our tests would run faster. The cost was determined to be justified, so we grew the testing cohort to 5% of the users in our top four markets.
Gradually, we figured out what in Spotify Now was causing users to quit the product. So, we removed those features and were able to roll out the remainder of the capabilities to the rest of the world with a more modest retention gain.
In the many retrospectives that followed to understand what mistakes we'd made (and what we had done correctly), we found failures in our perceptions of our customers, our teams, and other areas.
It turns out that one of our biggest problems was a process failure. We had a bug in our A/B testing framework. That bug meant that we had accidentally rolled out our Spotify Now test to a cohort participating in a very different trial. A trial to establish a floor on what having no advertising in the free product would do for retention, essentially giving our premium product away for free.
To Spotify's immense credit, instead of punishing me, my peers, and the team, we were rewarded for how we handled the failure. The lessons we learned from the mistakes of Spotify Now were immensely beneficial to the company. Moreover, those lessons produced some of the company's triumphs in the years that have followed, including Spotify's most popular curated playlists, Discover Weekly, Release Radar, Daily Mixes, and podcasts.
Putting this into practice at Avvo
If you think you would like to use these ideas at your company but are unsure where to start, I will describe what we did at Avvo. I joined the company as CTO after I left Spotify. When I joined, the company was already nine years old. It had a primarily monolithic architecture running in a single data center with minimal redundancy.
We did some things quickly to move to a more fail-safe world.
Moving from planning around objectives to planning around priorities
First, we worked to build a supportive culture that could handle the inevitable failures better. We moved from planning around specific deliverable commitments to organizing our work around priorities.
Suppose my specific achievements, my output, measure my performance. This way of measuring performance often creates problems.
Suppose I need to coordinate with another person, and their commitments do not align with mine. That situation will create tension. If the company's needs change, but my obligations do not, there is little incentive for me to reorient my work. Dependencies can thwart me from achieving my commitments, or I may need to hamper the company's priorities to achieve my own if they are not well-aligned.
People in leadership like quarterly goals or Management By Objectives because they create strict accountability. If I commit to doing something and it is not complete when I say it will be, I have failed even if it is no longer the right thing for me to do.
Suppose you think instead about aligning around priorities. In that case, those priorities may change from time to time. Still, if everyone is working against the same set of priorities, you can be sure that they are broadly doing the right things for the company. Aligning to priorities sets an expectation of outcome, not output.
Talk about failure with an eye to future improvement instead of blame
The senior leadership team must be in alignment with these approaches. The rest of the organization may not be initially. Leaders must communicate with a learning message rather than blame or punishment when discussing failure. People should know that the expectation is that they may fail. If they primarily try to avoid failure, they probably aren't thinking big enough. It is the message: "we want to see you fail, small, and we want to make sure we learn from that failure."
I created our "Fail Wall" slack channel to share the lessons from our failures. I sent a message to my organization, making it clear that I don't expect perfection. I shared my vision that we become a learning organization in town halls and one-on-ones.
Fail-safe architecture
Monoliths are natural when building a new company or when you have a small team. Monoliths are simple to make and more straightforward to deploy when you don't have multiple teams building together. As the codebase and organization grow, microservices become a better model.
It is critical to recognize when a monolith is becoming a challenge instead of an enabler. Microservices require a lot more infrastructure to support them. In addition, the effort to transition from one architecture to another is significant, so it is best to prepare before the need becomes urgent.
Avvo had already started moving to a microservices architecture, but a lack of investment stalled the transition. So, I increased investment in the infrastructure team. As a result, the team built tools that simplified creating, testing, monitoring, and deploying services. We then made rapid progress.
We also redesigned our organization to leverage the reverse Conway Maneuver, further accelerating the new architecture.
You can build a fail-safe / fail-smart team
In every company, I use the lessons I have shared in this article to build a culture where teams can innovate and learn from their users. It manifests differently with each group, but every team adopting these ideas has improved business outcomes and employee satisfaction. Work with your peers to adopt some of these ideas. Start small and grow. The process of adopting these concepts mirrors the product development process you are working to build.
If you decide it isn't a good fit for your company, you will have failed smart by failing small.
I will leave you with a final thought from Henry Ford.
"Failure is simply the opportunity to begin again, this time more intelligently." - Henry Ford
Upcoming talk
I’m giving a talk, “The path from Director to CTO: How to follow it, or how to mentor it,” at the LeadingEng conference in New York City in September. You can use the code “DISTROKID” to save 10% on your registration! More information and registration: https://leaddev.com/leadingeng-new-york
Thanks again for reading! If you find it helpful, please share it with your friends.

Buy on Amazon | Buy on Bookshop.org | Buy on Audible | Other stores